오랜만에 Data Science 카테고리에 글을 올리네요. 예전에 웹에서 데이터를 가지고 오는 간단한 방법을 이야기했던 적이 있습니다. 오늘은 그 글에서 이어지는 내용입니다. 웹상에서 어떤 입력폼에 글자를 입력한다든지, 접근해야할 상세 웹 주소가 보이지 않는다든지 등의 상황에서 유용하게 사용할 수 있는 도구가 selenium입니다.
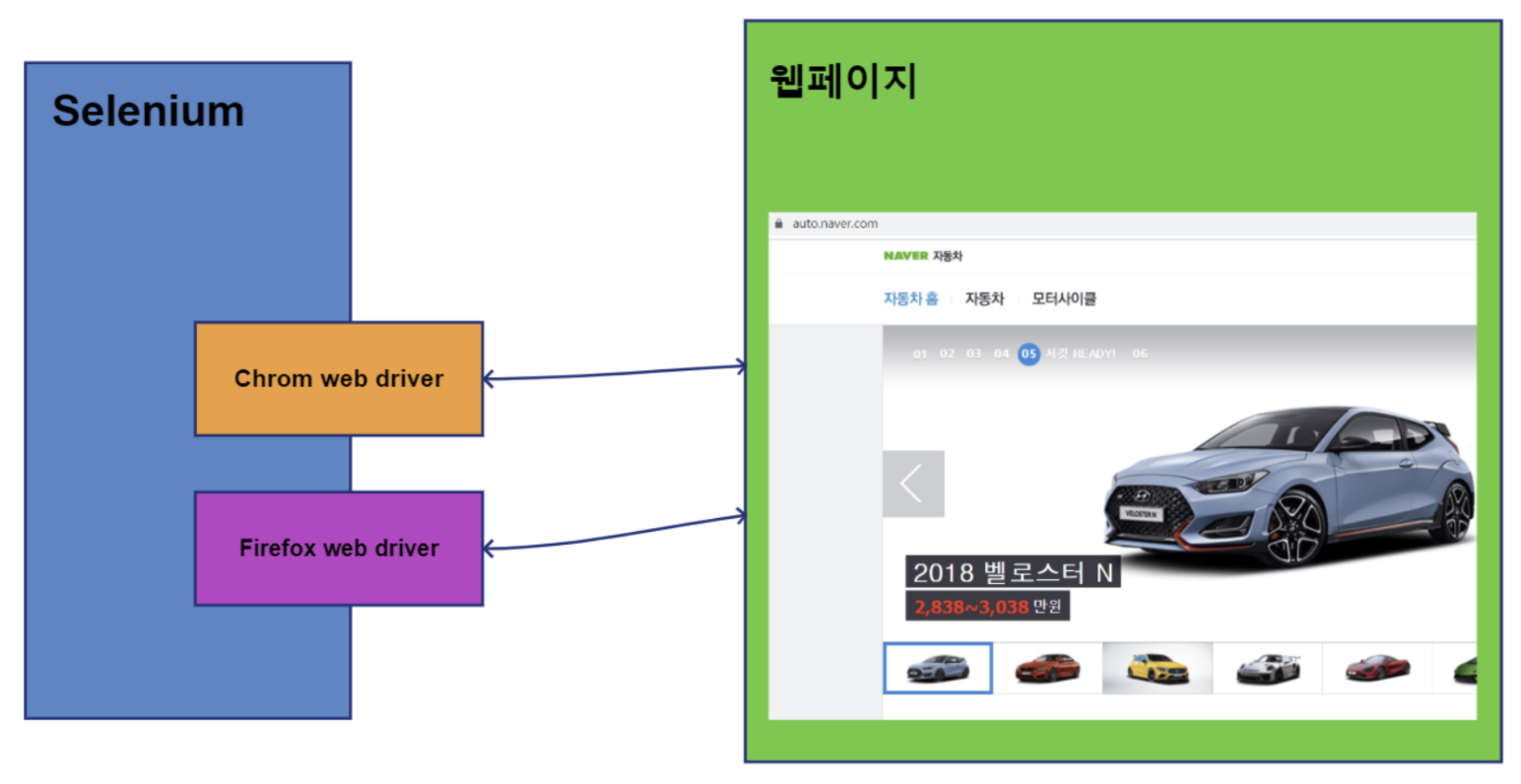
위 그림에 나타나있듯이 selenium은 사용하는 브라우저에 맞춰 드라이버를 실행합니다. 그러면 해당 드라이버가 웹페이지를 읽을 브라우저를 실행해서 나의 코드에 의해 제어되도록 되는 것입니다.

설치는 pip 명령으로 먼저 진행하구요. 아래 그림처럼 자신의 크롬 버전을 확인합니다. 우측 상단 점 세개를 클릭한 다음 도움말의 크롬 버전을 확인하시면 됩니다.

크롬드라이버 다운로드 사이트에서 자신의 크롬 버전에 맞춰 크롬 드라이버를 다운로드하시면 됩니다. 그런데 크롬은 위 그림처럼 크롬 버전을 확인하는 순간에 최신버전으로 업데이트를 시도하기 때문에 그냥 최신버전으로 업데이트를 하시고 그 후 크롬을 다시 시작하고 진행하는게 좋을 수도 있습니다.
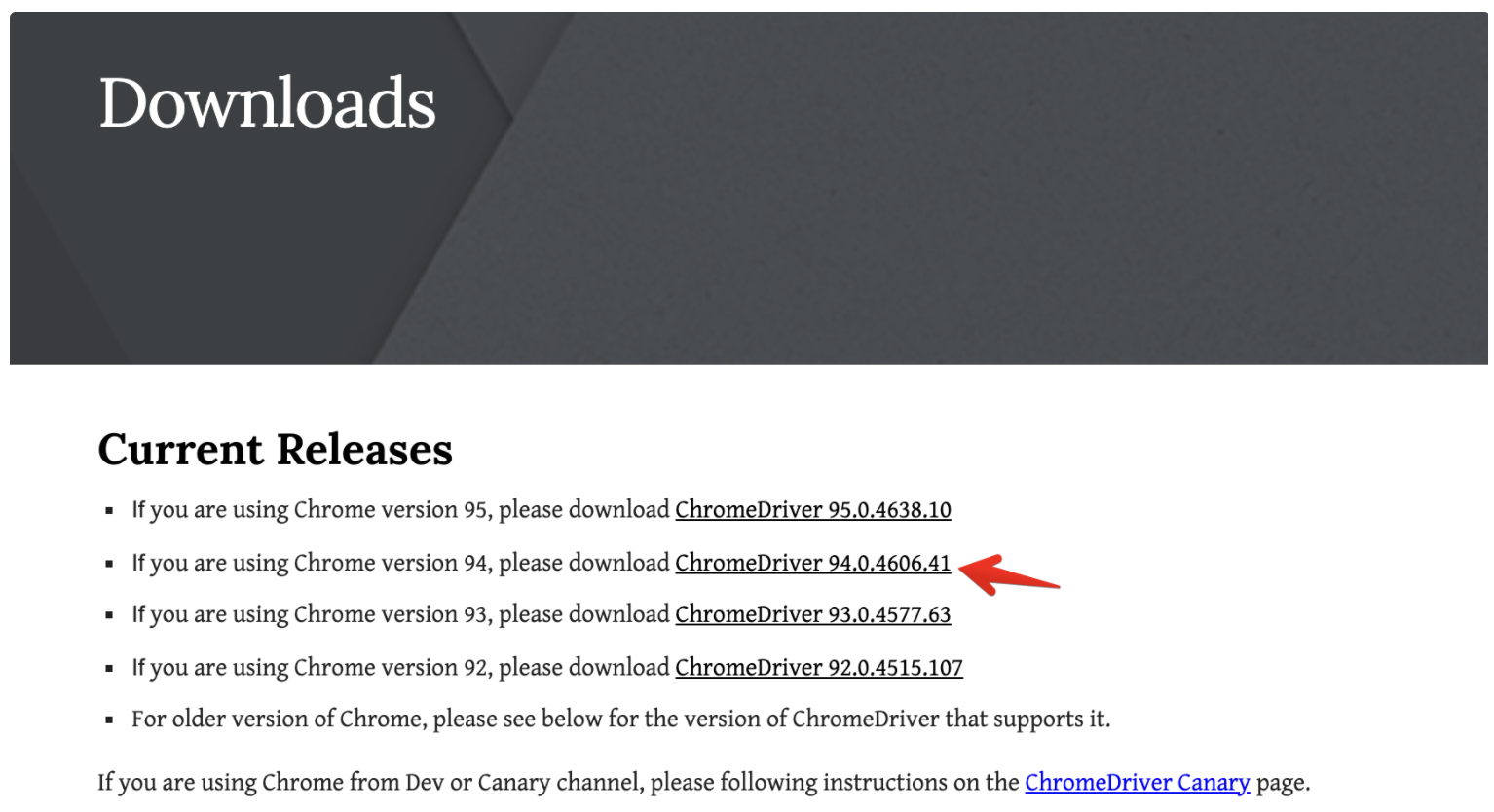
아무튼 저는 크롬 버전이 94이고, 위 그림에서 94로 시작하는 링크를 누르시면 됩니다.
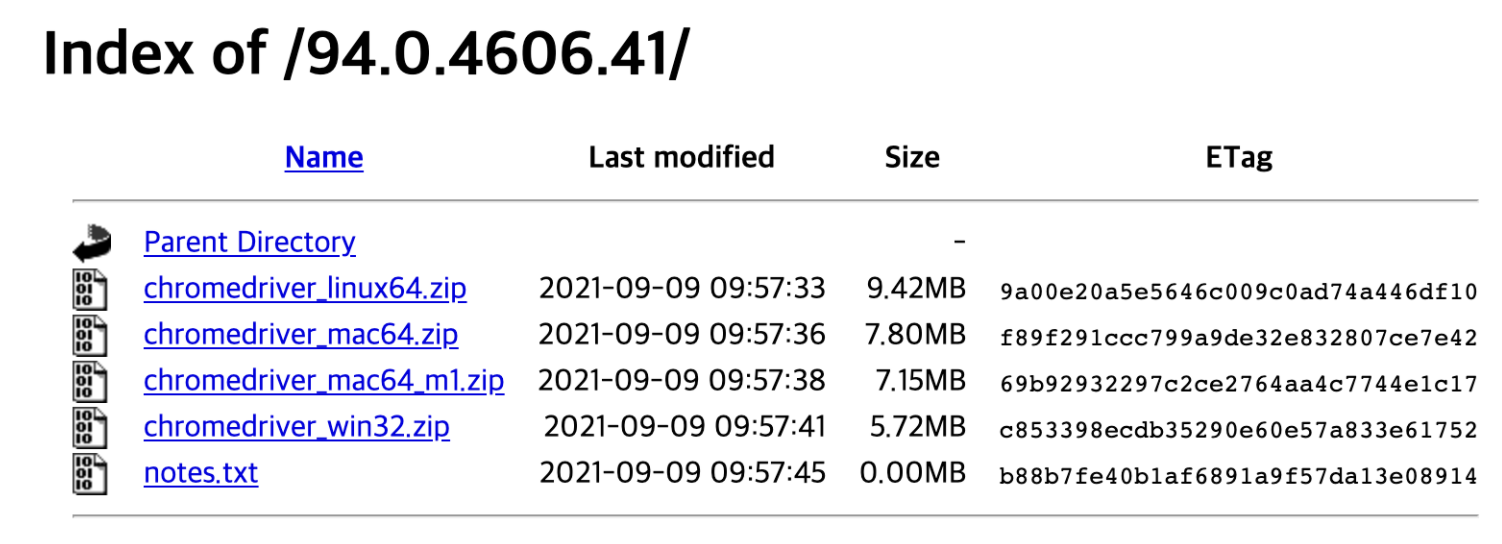
이제 나타는 위 그림의 사이트에서 자신의 OS에 맞는 크롬드라이버를 다운로드 받으면 됩니다. 그리고 받은 드라이버(파일 하나입니다)를 나의 소스코드와 같은 위치에 두면 됩니다.

이제 크롬 드라이버를 실행하고, 제 블로그로 접근하는 위의 코드를 실행합니다.

그러면 새 창이 뜨면서 크롬 드라이버가 제가 지정한 사이트에 접근을 합니다.

위 코드는 스크롤 가능한 높이를 알려주는 코드이고,

위 코드는 제일 하단으로 스크롤 하는 코드입니다.

웹 데이터를 가져오는 내용을 설명했던 글에서 안내한 크롬 개발자 도구가 있습니다. 그 글에 보면 중간쯤에 개발자 도구를 쓰서 웹 페이지의 위치에 해당하는 태그를 가져오는 과정을 설명했는데요. 그걸 이용해서 위 그림처럼 페이지를 지정하는 곳을 찾아서 그 곳의 XPath를 가져옵니다.

해당 xpath지점까지 스크롤하라는 코드가 위의 코드입니다.
실행하고 나면 위 그림처럼 잘 이동했음을 알 수 있습니다.
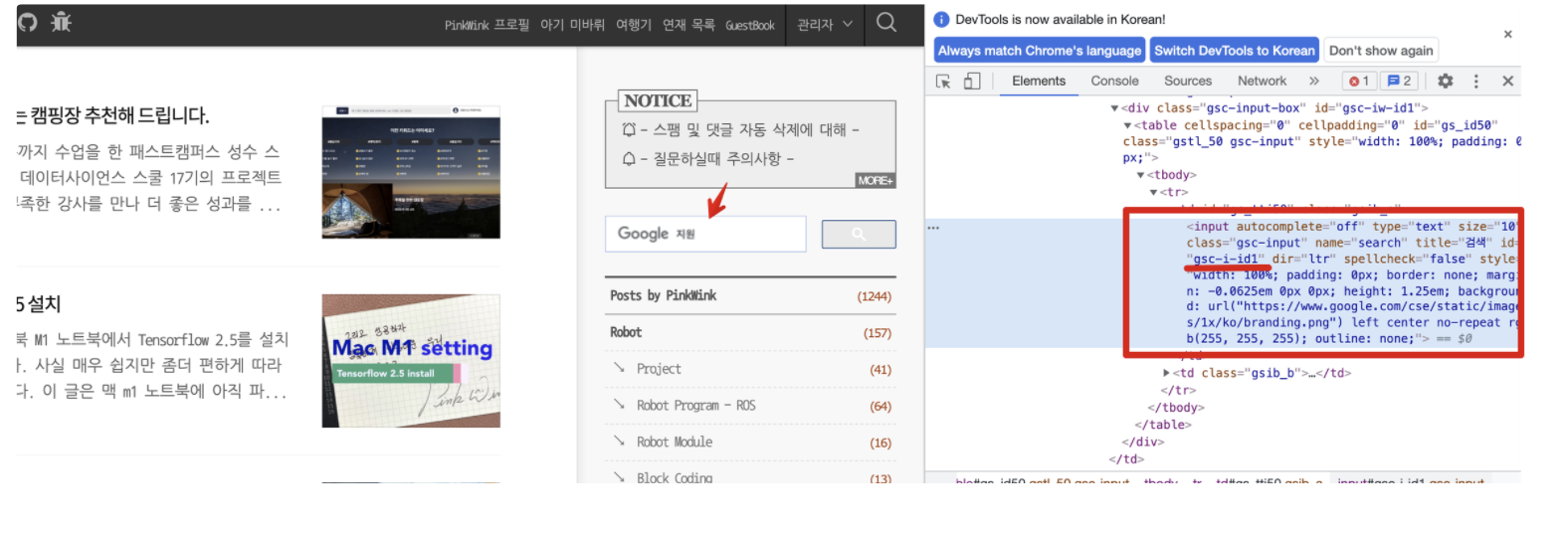
제 블로그는 위 그림의 화살표처럼 구글 검색창을 하나 가지고 있는데요. 개발자 도구에서 확인해보면 그 검색창의 id를 알 수 있습니다.

id를 이용해서 find_element_by_id 명령으로 해당 창에 접근할 수 있습니다. 거기에 send_keys 명령으로 data science라는 글자를 입력합니다.

그러면 저렇게 그 글자가 크롬 드라이버에 딱~ 하니 들어가 있죠.

이제 위 화면에 보이는 버튼을 눌러야 검색을 해주겠죠. 그 버튼의 xpath를 찾기 위해 크롬 개발자 도구에서 태그를 찾습니다.

그리고 오른쪽 버튼을 눌러 copy의 copy xpath를 선택하면 됩니다.

그 xpath를 find_element_by_xpath로 찾아서 위 코드처럼 그냥 click 해주면 됩니다^^

그러면 크롬 드라이버에서 저렇게 검색된 결과가 화면에 나타나는거죠.

해당 화면의 html 소스를 가져오고 싶으면 위 코드의 page_source를 가져오면 됩니다.
위 내용은 모두 아래 동영상으로 다시 다루고 있습니다.
'Theory > DataScience' 카테고리의 다른 글
| 소리나 음원, 음악 데이터에서 주파수 특성 분석 - librosa (8) | 2022.02.24 |
|---|---|
| Jupyter Notebook을 원격으로 접속하기 (7) | 2021.04.08 |
| Python scikit learn의 Label Encoder와 MinMax, Standard, Robust Scaler 이해하기 (6) | 2021.04.05 |
| Box Plot의 기초 (6) | 2021.03.24 |
| Colab에서 KoNLPy와 WordCloud 설정하기 (4) | 2021.01.15 |
| 한글 형태소 분석기 KoNLPy 사용을 위한 환경 설정 해보기 (8) | 2020.12.23 |
| 네이버 검색 결과를 API를 이용해서 쉽게 받아보자 (6) | 2020.10.13 |



